
|
Motion Prompting: Controlling Video Generation with Motion Trajectories
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez-Guevara, Carl Doersch, Yusuf Aytar, Michael Rubinstein, Chen Sun, Oliver Wang, Andrew Owens, Deqing Sun
[arXiv] [webpage]
|

|
Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation
Gen2Act: Human Video Generation in Novel Scenarios
enables Generalizable Robot Manipulation
[arXiv] [webpage]
|
|
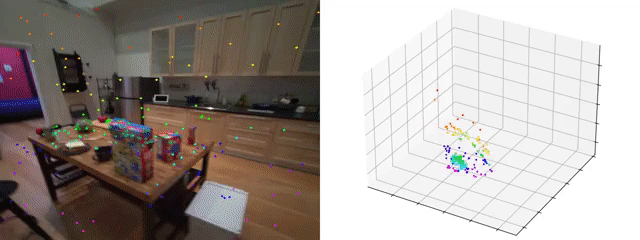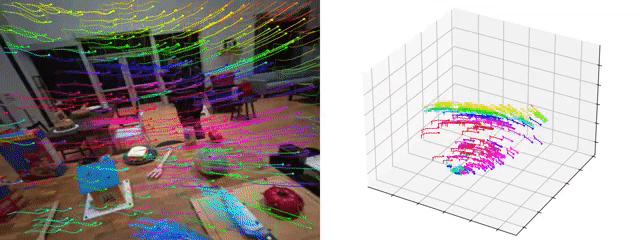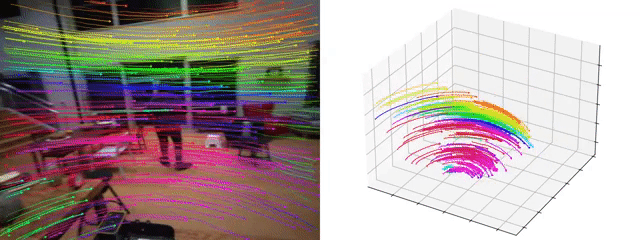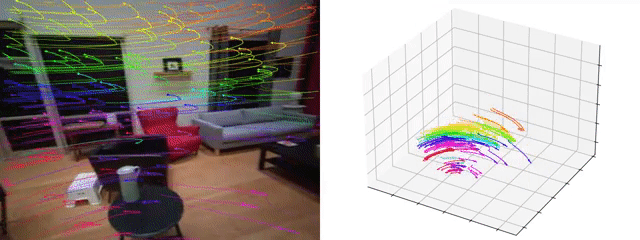
TAPVid-3D: A Benchmark for Tracking Any Point in 3D
Skanda Koppula, Ignacio Rocco, Yi Yang, Joe Heyward, Joao Carreira, Andrew Zisserman, Gabriel Brostow, Carl Doersch
[arXiv] [github] [webpage]
|
|
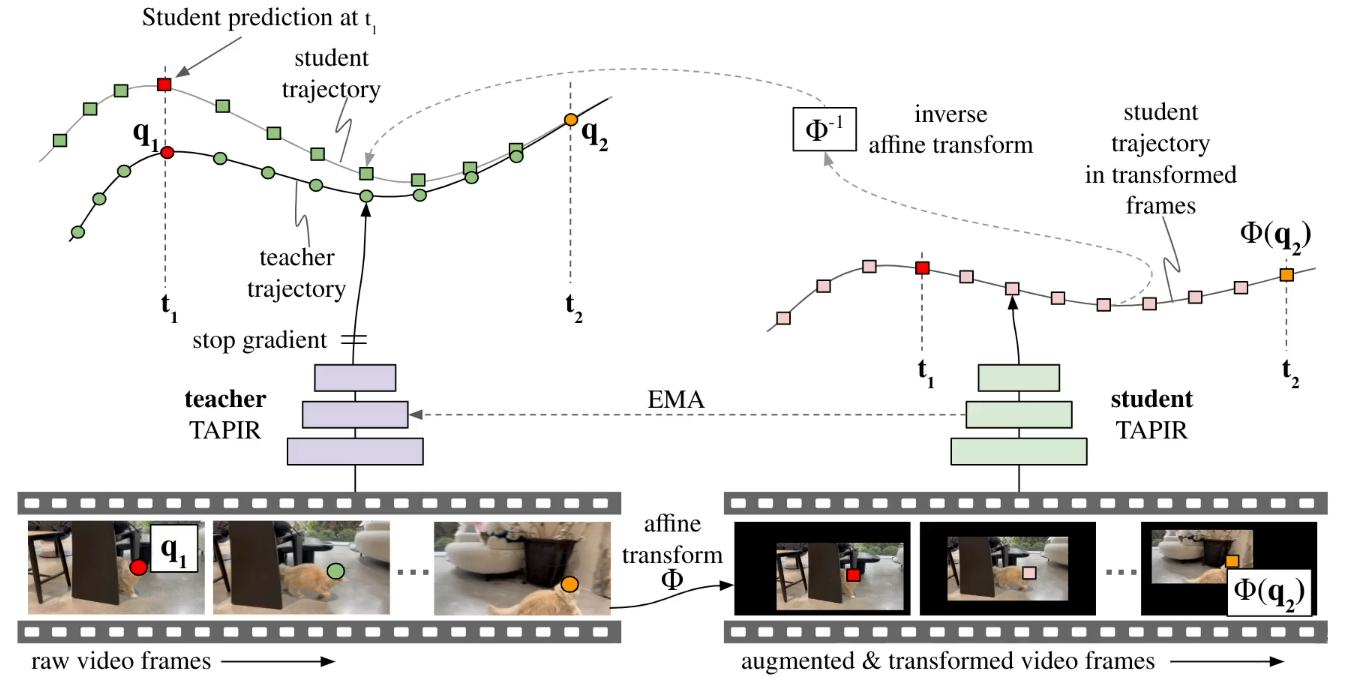
BootsTAP: Bootstrapped Training for Tracking-Any-Point
Carl Doersch, Pauline Luc, Yi Yang, Dilara Gokay, Skanda Koppula, Ankush Gupta, Joseph Heyward, Ignacio Rocco, Ross Goroshin, João Carreira, Andrew Zisserman in ACCV 2024
[arXiv] [github] [webpage]
|

|
RoboTAP: Tracking Arbitrary Points for Few-Shot Visual Imitation
Mel Vecerik, Carl Doersch, Yi Yang, Todor Davchev, Yusuf Aytar, Guangyao Zhou, Raia Hadsell, Lourdes Agapito, Jon Scholz
in ICRA 2024 [arXiv]
|

|
TAPIR: Tracking Any Point with per-frame Initialization and temporal Refinement
Carl Doersch, Yi Yang, Mel Vecerik, Dilara Gokay, Ankush Gupta, Yusuf Aytar, João Carreira, Andrew Zisserman
in ICCV 2023 [arXiv] [github]
|
|
The Perception Test
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Recasens Continente, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Doersch, Tatiana Matejovicova, Yury Sulsky, Antoine Miech, Alex Frechette, Hanna Klimczak, Raphael Koster, Junlin Zhang, Stephanie Winkler, Yusuf Aytar, Simon Osindero, Dima Damen, Andrew Zisserman, Joao Carreira
ECCV/ICCV Workshop Series [v1]
|

|
TAP-Vid: A Benchmark for Tracking Any Point in a Video
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adrià Recasens, Lucas Smaira, Yusuf Aytar, João Carreira, Andrew Zisserman, Yi Yang
in NeurIPS Datasets and Benchmarks 2022 [arXiv] [github]
|

|
Input-level Inductive Biases for 3D Reconstruction
Wang Yifan, Carl Doersch, Relja Arandjelovic, Joao Carreira, Andrew Zisserman
in CVPR 2022 [arXiv]
|

|
Kubric: A Scalable Dataset Generator
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J. Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, Thomas Kipf, Abhijit Kundu, Dmitry Lagun, Issam Laradji, Hsueh-Ti (Derek) Liu, Henning Meyer, Yishu Miao, Derek Nowrouzezahrai, Cengiz Oztireli, Etienne Pot, Noha Radwan, Daniel Rebain, Sara Sabour, Mehdi S. M. Sajjadi, Matan Sela, Vincent Sitzmann, Austin Stone, Deqing Sun, Suhani Vora, Ziyu Wang, Tianhao Wu, Kwang Moo Yi, Fangcheng Zhong, Andrea Tagliasacchi
in CVPR 2022 [arXiv] [github]
|

|
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Henaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, Joao Carreira
in ICLR 2022 [arXiv]
|

|
Inferring a Continuous Distribution of Atom Coordinates from Cryo-EM Images using VAEs
Dan Rosenbaum, Marta Garnelo, Michal Zielinski, Charlie Beattie, Ellen Clancy, Andrea Huber, Pushmeet Kohli, Andrew W. Senior, John Jumper, Carl Doersch, S. M. Ali Eslami, Olaf Ronneberger, Jonas Adler
in NeurIPS 2021 workshop on Machine Learning in Structural Biology [arXiv]
|

|
CrossTransformers: spatially-aware few-shot transfer
Carl Doersch, Ankush Gupta, Andrew Zisserman
in NeurIPS 2020 [arXiv]
|

|
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, Michal Valko
in NeurIPS 2020 (Oral) [arXiv]
|

|
Data-Efficient Image Recognition with Contrastive Predictive Coding
Olivier J. Hénaff, Aravind Srinivas, Jeffrey De Fauw, Ali Razavi, Carl Doersch, S. M. Ali Eslami, Aaron van den Oord
in ICML 2020 [arXiv]
|

|
Sim2real transfer learning for 3D human pose estimation: motion to the rescue
Carl Doersch, Andrew Zisserman
in NeurIPS 2019 [arXiv]
|

|
Exploiting temporal context for 3D human pose estimation in the wild
Anurag Arnab, Carl Doersch, Andrew Zisserman
in CVPR 2019 [arXiv]
|

|
Video Action Transformer Network
Rohit Girdhar, João Carreira, Carl Doersch, Andrew Zisserman
in CVPR 2019 [arXiv]
A Better Baseline for AVA
Rohit Girdhar, João Carreira, Carl Doersch, Andrew Zisserman
in CVPR 2018 ActivityNet Workshop [arXiv]
|
|
|
Kickstarting Deep Reinforcement Learning
Simon Schmitt, Jony Hudson, Augustin Zidek, Simon Osindero, Carl Doersch, Wojciech Czarnecki, Joel Leibo, Heinrich Kuttler, Andrew Zisserman, Karen Simonyan, Ali Eslami
in NIPS 2018 Reinforcement Learning Workshop [arXiv]
|

|
Learning Visual Question Answering by Bootstrapping Hard Attention
Mateusz Malinowski, Carl Doersch, Adam Santoro, Peter Battaglia
in ECCV 2018 [arXiv]
The Visual QA Devil in the Details: The Impact of Early Fusion and Batch Norm on CLEVR
Mateusz Malinowski, Carl Doersch
in ECCV 2018 Workshop on Shortcomings in Vision and Language [arXiv]
|

|
Multi-task Self-Supervised Visual Learning
Carl Doersch and Andrew Zisserman
in ICCV 2017 [arXiv]
[Show BibTex]
@inproceedings{doersch2017multitask,
title = {Multi-task Self-Supervised Visual Learning},
author = {Doersch, Carl and Zisserman, Andrew},
booktitle = {International Conference on Computer Vision},
year = {2017},
}
|

|
Supervision Beyond Manual Annotations for Learning Visual Representations
Carl Doersch.
Carnegie Mellon Thesis Dissertation [pdf]
[Show BibTex]
@phdthesis{doersch2016unsupervised,
title = {Supervision Beyond Manual Annotations for Learning Visual Representations},
author = {Doersch, Carl},
school = {Carnegie Mellon University},
year = {2016},
}
|

|
Tutorial on Variational Autoencoders
Carl Doersch.
Arxiv Tech Report, June 2016 [arXiv]
[Show BibTex]
@article{doersch2016tutorial,
title = {Tutorial on Variational Autoencoders},
author = {Doersch, Carl},
journal = {arXiv preprint arXiv:1606.05908},
year = {2016},
}
|

|
An Uncertain Future: Forecasting from Static Images using Variational Autoencoders
Jacob Walker, Carl Doersch, Abhinav Gupta, and Martial Hebert.
in ECCV 2016 [webpage] [arXiv]
[Show BibTex]
@inproceedings{walker2016uncertain,
title = {An Uncertain Future: Forecasting from Static Images using Variational Autoencoders},
author = {Walker, Jacob and Doersch, Carl and Gupta, Abhinav and Hebert, Martial},
booktitle = {European Conference on Computer Vision},
year = {2016},
}
|

|
Data-dependent Initializations of Convolutional Neural Networks
Philipp Krähenbühl, Carl Doersch, Jeff Donahue, and Trevor Darrell.
ICLR, 2016 [arxiv]
|

|
Unsupervised Visual Representation Learning by Context Prediction
Carl Doersch, Abhinav Gupta, and Alexei A. Efros.
in ICCV 2015 (oral) [webpage] [arXiv]
[Show BibTex]
@inproceedings{doersch2015unsupervised,
title = {Unsupervised Visual Representation Learning by Context Prediction},
author = {Doersch, Carl and Gupta, Abhinav and Efros, Alexei A.},
booktitle = {International Conference on Computer Vision},
year = {2015},
}
|

|
Context as Supervisory Signal: Discovering Objects with Predictable Context
Carl Doersch, Abhinav Gupta, and Alexei A. Efros.
In ECCV 2014
[Show BibTex]
@inproceedings{doersch2014context,
title = {Context as Supervisory Signal: Discovering Objects with Predictable Context},
author = {Doersch, Carl and Gupta, Abhinav and Efros, Alexei A.},
booktitle = {European Conference on Computer Vision},
year = {2014},
}
|

|
Mid-Level Visual Element Discovery as Discriminative Mode Seeking
Carl Doersch, Abhinav Gupta, and Alexei A. Efros.
In NIPS 2013
[Show BibTex]
@inproceedings{doersch2013mid,
title = {Mid-Level Visual Element Discovery as Discriminative Mode Seeking},
author = {Doersch, Carl and Gupta, Abhinav and Efros, Alexei A.},
booktitle = {Neural Information Processing Systems (NIPS)},
year = {2013},
}
|

|
What Makes Paris Look like Paris?
Carl Doersch, Saurabh Singh, Abhinav Gupta, Josef Sivic, and Alexei A. Efros.
In SIGGRAPH 2012 (oral)
Republished on the cover of the CACM magazine Dec. 2015
[Show BibTex]
@article{doersch2012what,
title = {What Makes Paris Look like Paris?},
author = {Carl Doersch and Saurabh Singh and Abhinav Gupta and Josef Sivic and Alexei A. Efros},
journal = {ACM Transactions on Graphics (SIGGRAPH)},
volume = {31},
number = {4},
year = {2012},
}
@article{doersch2015makes,
title={What makes Paris look like Paris?},
author={Doersch, Carl and Singh, Saurabh and Gupta, Abhinav and Sivic, Josef and Efros, Alexei A},
journal={Communications of the ACM},
volume={58},
number={12},
pages={103--110},
year={2015},
publisher={ACM}
}
|

|
Bounding the Probability of Error for High Precision Optical Character Recognition
Gary B. Huang, Andrew Kae, Carl Doersch, and Erik Learned-Miller.
In JMLR 2012 [pdf]
[Show BibTex]
@article{huang2012bounding,
title={Bounding the Probability of Error for High Precision Optical Character Recognition},
author={Huang, G.B. and Kae, A. and Doersch, C. and Learned-Miller, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={363--387},
year={2012}
}
Improving state-of-the-art OCR through high-precision document-specific modeling.
Andrew Kae, Gary B. Huang, Carl Doersch, and Erik Learned-Miller.
In CVPR 2010 [pdf]
[Show BibTex]
@INPROCEEDINGS{kae10improving,
author = {Andrew Kae and Gary B. Huang and Carl Doersch and Erik Learned-Miller},
title = {Improving state-of-the-art OCR through high-precision document-specific modeling.},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2010},
month = {Jun}
}
|
|
 |


